先前任务不足
传统LLM VLMS没有建立在涉及空间关系、适用性、物理、布局等丰富概念的3D物理世界中
实验目标
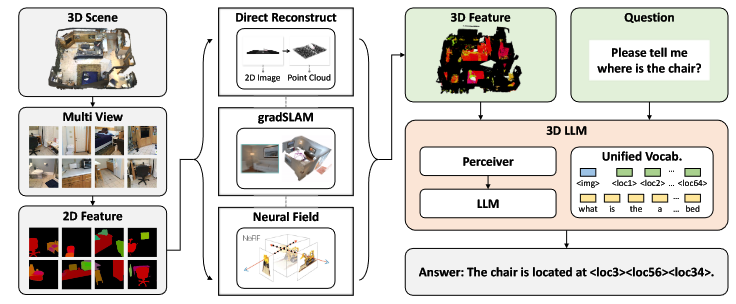
3D点云及其特征作为输入,并执行包括字幕、密集字幕、3D问题回答、任务分解、3D基础、3D辅助对话、导航等多样的3D相关任务
实验设置
3D特征提取器:从渲染的多视图图像中获取3D特征
2D VLMs作为骨干来训练3D-LLMs
3D定位机制:3D-LLMs可以更好地捕捉3D空间信息
介绍
多模态LLM(例如Flamingo ,BLIP-2 ):
将图像和视频与LLM对齐,赋予了理解和推理二维图像的能力,缺乏更丰富的概念,如空间关系、适应性、物理和互动等
对此改进:
引入一整套可接受三维表示(即带有其特征的三维点云)的新的三维LLMs,以执行一系列三维相关任务。
接收场景的三维表示作为输入
优势:
(1)整个场景的长期记忆可以存储在整体的三维表示中,而不是片段性部分视图的观察。
(2)可以通过三维表示推理出适应性和空间关系等三维属性,
独特的数据生成管道:生成大规模的与语言配对的3D数据(挑战1)
具体来说,利用ChatGPT 并设计了三种高效的提示程序,用于3D数据和语言之间的交流。通过这种方式,能够获得包括但不限于3D字幕,密集字幕,3D问题回答,3D任务分解,3D基础和3D辅助对话等各种任务的30万条3D语言数据
对比学习范式(例如CLIP)
实现2D图像和语言之间的对齐, 但消耗了大量数据、时间和GPU资源
2D多视图图像构建3D特征(例如,概念融合,3D-CLR])
视觉语言模型(例如,BLIP-2,Flamingo)
利用2D预训练的CLIP特征来训练它们的VLMs
改进
3D特征提取器:获得具有与3D-LLMs的语言特征对齐的有意义的3D特征(挑战2)
从渲染的多视图图像的2D预训练特征构建3D特征,由于提取的3D特征映射到与2D预训练特征相同的特征空间,可以无缝地使用2D VLMs作为我们的骨干,并将3D特征输入以有效地训练3D-LLMs
3D定位机制:将3D位置嵌入附加到提取的3D功能上,以更好地编码空间信息。此外,将一系列位置令牌附加到3D-LLMs上,可以通过输出位置令牌来训练特定场景中对象的语言描述。
相关工作
- 大语言模型(LLM)密切相关,如GPT-3和PaLM
- 视觉语言预训练模型:应用于视觉问题回答、字幕和指代表达理解
- 3D和语言:ScanQA要求模型回答与3D世界相关的问题;ScanRefer要求模型定位文本表达所指的区域;3D字幕 测试模型生成描述3D场景的字幕的能力。
改进目标:
然而,这些3D任务及其相应的模型通常是特定于任务的,并且只能处理在训练集的相同分布内的情况,无法实现泛化。与它们不同,我们的目标是构建一个能够同时处理不同任务并启用新能力,如3D助手的3D模型。
3D语言数据生成(训练语言数据准备)
- 基于盒子演示指令的提示。我们输入3D场景中房间和物体的轴对齐边界框(AABB),提供关于场景的语义和空间位置的信息。然后向GPT模型提供特定指令,以生成多样化的数据。提供0-3个GPT模型的示范演示示例,展示它被指示生成的数据类型。
- 基于ChatCaptioner的提示。利用类似于的技术,其中ChatGPT被提示向图像提出一系列信息性的问题,而BLIP-2回答这些问题。为了收集3D相关数据,向BLIP-2输入不同视角的图像,指示ChatGPT提出问题,并收集不同区域的信息,以形成整个场景的全局3D描述。
- 基于修订的提示。可用于将一种类型的3D数据转移到另一种。给出提示管道,GPT能够生成各种类型的3D语言数据
生成过程:学习速率从0线性增加到10-4,在前5000步内保持恒定,然后在训练期间保持不变。该模型在8个A100上进行训练。批量大小为16。我们使用分布式数据并行(DDP)来训练模型。
3D-LLM
从2D多视图图像中提取3D特征。使用这些对齐方法,我们可以使用预训练图像编码器来提取图像特征,然后将这些特征映射到3D数据上。由于预训练的图像特征作为2D VLMs的输入,相同特征空间的映射的3D特征也可以无缝地输入到预训练的2D VLMs中,而这些VLMs被用作我们训练3D-LLMs的骨干。
提出了一种3D定位机制,以提高模型捕捉3D空间信息的能力
3D特征提取器
训练3D-LLMs的第一步是构建可以与语言特征对齐的有意义的3D特征
从头开始预训练这样的特征学习器是困难的,因为在数量和多样性方面,不存在可与互联网规模的图像语言对相媲美的3D语言资产。相反,已经提出了许多方法来从2D多视图图像中提取3D特征。受到这些工作的启发,通过在几个不同的视图中渲染3D场景来提取3D点的特征,并从渲染图像特征构建3D特征。
- 直接重构。利用地面真实相机矩阵直接重构点云,从3D数据渲染的rgbd图像。这些特征直接映射到重构的3D点上。此方法适用于具有完美相机姿态和内参的渲染rgbd数据。
- 特征融合。使用gradslam将2D特征融合到3D地图中。与密集映射方法不同,特征融合不仅融合深度和颜色,而且融合特征。此方法适用于带有嘈杂深度图渲染或嘈杂相机姿态和内参的3D数据。
- 神经场。利用神经体素场构建3D紧凑表示。具体来说,场中的每个体素除了密度和颜色外,还有一个特征。然后,使用MSE损失在射线中对齐3D特征和像素中的2D特征。此方法适用于具有RGB渲染但没有深度数据以及嘈杂相机姿态和内参的3D数据。
训练3D-LLM
2D VLMs作为骨干
考虑到3D特征提取器可以将3D特征映射到与2D图像相同的特征空间,使用这些2D VLMs作为我们的骨干是合理的。
现有的感知器架构利用不对称注意机制将输入迭代地提炼到紧凑的潜在瓶颈中,使其能够处理任意输入大小的非常大的输入,因此可以处理不同的模态(Flamingo)
BLIP-2还利用了一种类似的结构,称为QFormer。从冻结图像编码器输出的2D图像特征被展平并发送到感知器以生成固定大小的输入。
3D定位机制
由两部分组成:
- 用位置嵌入增强3D特征 除了从2D多视图特征聚合的3D特征之外,我们还向特征添加位置嵌入。
- 用位置令牌增强LLM词汇 为了使3D空间位置与LLMs对齐,我们建议在词汇中嵌入3D位置
实验
- ScanQA数据集 held-out experiment
- 3DMV-VQA和物体导航 held-out experiment
- 有关定位和密集字幕 held-out experiment
- 更多割减研究;
- 更多定性示例
架构
主干选择
- Flamingo 9B,
- BLIP-2 Vit-g Opt2.7B
- BLIP-2 Vit-g FlanT5-XL
对于BLIP-2,从LAVIS库中发布的BLIP-2 checkpoints初始化模型,并微调QFormer的参数。3D特征是1408维的特征,与BLIP-2使用的EVA_CLIP隐藏特征维度相同。保持LLMs的大部分部分(即Opt和FlanT5)冻结,除了输入和输出嵌入中新增的位置令牌的权重。
对于Flamingo,从OpenFlamingo存储库中发布的Flamingo9B checkpoints初始化模型。微调感知器、门控交叉注意层的参数,以及输入和输出嵌入中额外位置令牌的权重。3D特征是1024维的特征,与Flamingo使用的CLIP隐藏特征维度相同。
训练和评估数据集和协议
数据集分为两种类型,即held-in数据集和held-out数据集
具体而言,3D语言数据生成管道生成了多个任务的held-in数据集。将数据集分为训练/验证/测试集(8:1:1)。
利用保留数据集的训练集来对基础3D-LLM进行预训练,它们的验证和测试集可以用于保留数据集的评估。
在预训练期间,混合所有任务的保留数据集。模型使用标准语言建模损失进行训练以输出响应。另一方面,非保留数据集不用于基础3D-LLM的训练。
使用了两个非保留3D问答数据集进行非保留评估:ScanQA和3DMV-VQA。
我们利用保留数据集的训练集来对基础3D-LLM进行预训练,它们的验证和测试集可以用于保留数据集的评估。在预训练期间,我们混合了所有任务的保留数据集。模型使用标准语言建模损失进行训练以输出响应。另一方面,非保留数据集不用于基础3D-LLM的训练。我们使用了两个非保留3D问答数据集进行非保留评估:ScanQA和3DMV-VQA。
Held-out 评估
- ScanQA是基准测试中使用VoteNet获得对象提议的最先进方法,然后将它们与语言嵌入融合。
- ScanRefer+MCAN是一个基准,用于识别所指对象,然后将MCAN模型应用于定位对象周围的图像。
- VoteNet+MCAN在3D空间中检测对象,提取它们的特征,并将其用于标准的VQA模型。
注意:这些基准模型都从预训练的定位模块中提取明确的对象表示
基于LLM的基线
- LLaVA是一种视觉指令调整,它连接了视觉编码器和LLM以实现通用视觉和语言理解。使用它的预训练模型,并对数据集进行zero-shot评估。(使用LLaVA 13B模型)
- 单图像+预训练VLMs使用我们的2D VLM主干(即,flamingo和BLIP-2),用单个图像特征替换3D-LLMs的3D输入来训练模型,然后在ScanQA数据集上进行微调。
- 多视图图像+预训练的VLMs使用我们的2D VLM主干,用多视图图像的串联特征替换3D-LLMs的3D输入来训练模型,然后在ScanQA数据集上进行微调。
报告BLEU、ROUGE-L、METEOR、CIDEr以进行强大的答案匹配。我们还使用确切匹配(EM)度量。
补充
BLEU (Bilingual Evaluation Understudy)
BLEU 是一种评估机器翻译质量的指标,通过比较机器翻译输出和人工翻译的参考译文来工作。它主要关注词汇的准确性 和完整性,通过计算机器翻译输出中的n-gram与参考翻译中的n-gram的匹配度来评分。BLEU分数越高表示翻译质量越高。
ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation - Longest Common Subsequence)
ROUGE-L 是用于评估自动文本摘要或机器翻译的性能的一系列指标中的一种,特别是通过最长公共子序列(LCS)来衡量。它侧重于召回率,即参考摘要中的信息在生成摘要中被覆盖的程度。ROUGE-L计算生成的摘要和参考摘要之间最长公共子序列的长度,用于评估内容的一致性。
METEOR (Metric for Evaluation of Translation with Explicit ORdering)
METEOR是另一种评估机器翻译质量的指标,设计时考虑了BLEU的一些局限性。METEOR不仅比较单词精确匹配,还考虑了同义词和词形变化的匹配,以及单词匹配的顺序。这使得METEOR在某些情况下比BLEU更能准确反映翻译的质量。
CIDEr (Consensus-based Image Description Evaluation)
虽然CIDEr主要是为评估图像描述任务(即图像标注)设计的,但其核心思想也可以用于评估文本生成任务。CIDEr通过考虑词汇的独特性和句子的信息量来评估生成的描述与一组参考描述之间的相似度。这是通过计算词汇的TF-IDF加权n-gram匹配来实现的。
确切匹配 (EM, Exact Match)
确切匹配是评估问答系统中一个更直接的指标,它衡量系统生成的答案与参考答案是否完全一致。如果系统的答案和参考答案完全相同(考虑到一些微小的差异,如大小写和标点),则认为是确切匹配。
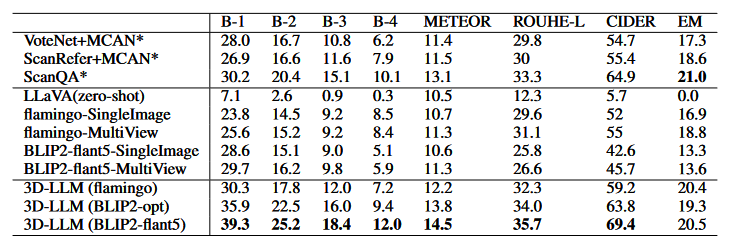
表1中报告了ScanQA验证集的结果

表2中报告了测试集的结果
实验结果
在BLEU-1方面,我们的模型在验证集上优于最先进的ScanQA模型约9%,在测试集上约7%。
对于CIDER,相对于ScanQA报告了约5%的增益,并且比其他基于3D的基线要高得多。
结果表明通过将3D注入LLMs,模型可以生成与ground-truth答案更相似的答案。
此外,基于3D的基线使用VoteNet等物体检测器对对象进行分割,然后将每个对象的特征发送到其模型中,而我们的输入是整体的3D特征,没有明确的对象表示。这表明即使没有明确的对象表示,我们的模型也可以执行关于对象及其关系的视觉推理。然后,我们检查2D VLMs是否具有相同的能力。我们发现,将单视图图像或多视图图像作为输入,与3D-LLMs相比,性能大大下降。具体而言,多视图图像还包含有关整个场景的信息。然而,与3D-LLMs相比,它们的性能要低得多,可能是因为多视图图像的特征是杂乱无章的,因此丢失了3D相关的信息。
更为广泛的评估
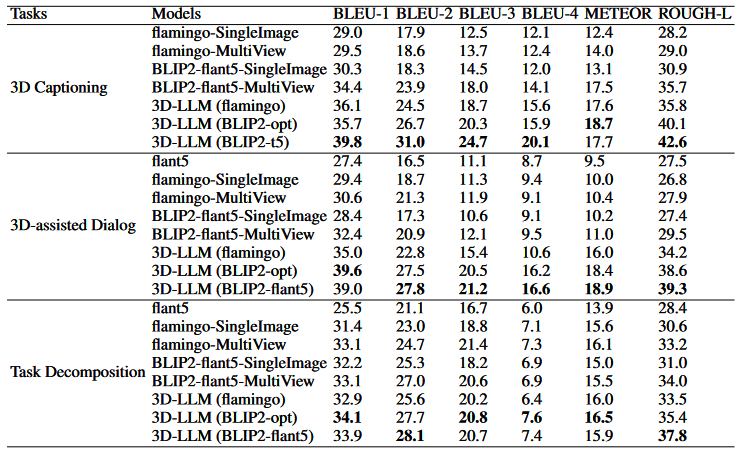
涉及三个任务的数据集:3D字幕、3D辅助对话和任务分解。
基线包括2D VLMs作为held-in评估。我们添加了一个仅语言的基线:FlanT5,它检验了LLMs在没有任何视觉输入的情况下完成这些任务的能力。为了评估响应的质量,我们包括BLEU、ROUGEL、METEOR、CIDEr作为我们的评估标准。我们在表3中报告了留存评估的表现。从表中我们可以看到,3D-LLMs能够生成高质量的响应,胜过了2D VLMs和仅语言的LLMs。
补充
held-in内部评估实验旨在评估深度学习模型在训练数据上的性能表现,以便了解模型在已知数据集上的表现如何,并且可以用来监控模型在训练过程中的训练情况。
held-out外部评估实验旨在评估深度学习模型在未知数据上的泛化能力,即模型在未见过的数据上的表现。这是为了确认模型是否能够在实际应用中有效地工作。
结论
在本文中提出了一种新的3D-LLM家族,可以将3D表示作为输入,并生成响应。
我们介绍了一系列3D语言数据生成管道,以生成30万个3D语言对的数据集,用于训练我们的3D-LLMs,包括密集字幕、3D问题回答、任务分解、3D定位、3D辅助对话、导航等。我们的3D-LLMs利用2D预训练的VLMs作为骨干和一种新颖的3D定位机制。
实验证明,我们的3D-LLMs在ScanQA数据集上优于最先进的基线模型,并能执行多样的3D相关任务。一个局限性是3D特征提取器依赖于2D多视图图像,因此所有3D场景都需要呈现,以便它们可以在3D-LLMs中进行训练,这引入了额外的渲染过程。




