简介
1.1 序言
一台机器不可能做到性能无限扩展,也无法抵御断电、断网、火灾、地震、甚至数据中心彻底毁坏等场景。这些中间件系统背后实际上一个服务器集群在对外提供服务,他们的目标便如此:在存在网络分区的分布式的场景下,通过合理的设计对外屏蔽复杂的分布式场景,提供性能可以随着服务器数量变化而线性变化,具备故障转移,故障自动恢复,对外提供功能却又像是运行在单核单CPU机器上,满足线性一致性的系统。
1.2 分布式系统挑战
人们需要获得更高的计算性能。可以这么理解这一点,大量的计算机意味着大量的并行运算,大量CPU、大量内存、以及大量磁盘在并行的运行。而单台机器并不能做到无限添加CPU,内存等物理资源。
另一个人们构建分布式系统的原因是,我们需要能够支持容错(tolerate faults)的系统,比如两台计算机运行完全相同的任务,其中一台发生故障,可以切换到另一台,如果是单机服务,发生断电,系统故障时,那么整个系统服务便不可用,直到有人手动来处理问题并重启服务。在金融,电力,通信等某些重要场景中,每一秒钟的系统瘫痪便会造成几百万,甚至千万级的损失。所以在某些重要场景中,采用分布式系统的目标便是为了实现容错,在某些相当重要的场景,甚至会为了容错牺牲部分性能。
第三个原因是,一些问题天然在空间上是分布的。例如银行转账,我们假设银行A在纽约有一台服务器,银行B在伦敦有一台服务器,这就需要一种两者之间协调的方法。所以,有一些天然的原因导致系统是物理分布的。
最后一个原因是,人们构建分布式系统来达成一些安全的目标。比如有一些代码并不被信任,但是你又需要和它进行交互,这些代码不会立即表现的恶意或者出现bug。你不会想要信任这些代码,所以你或许想要将代码分散在多处运行,这样你的代码在另一台计算机运行,我的代码在我的计算机上运行,我们通过一些特定的网络协议通信。所以,我们可能会担心安全问题,我们把系统分成多个的计算机,这样可以限制出错域。
1.3 可扩展性
通常来说,构建分布式系统的目的是为了获取可扩展的加速,或者实现单机难以到达的存储或者计算水平。所以,这里的可扩展性指的是,如果我用一台计算机解决了一些问题,当我买了第二台计算机,我只需要一半的时间就可以解决这些问题,或者说同样的时间内可以解决两倍数量的问题。两台计算机构成的系统如果有两倍性能或者吞吐能力便是指这里所说的扩展性。即:系统的计算、吞吐等性能随着计算机数量线性变化。
假设建立了一个常规网站,一般来说一个网站有一个 HTTP服务器,还有一些用户和浏览器,用户与一个基于Python或者PHP的web服务器通信,web服务器进而跟一些数据库进行交互。
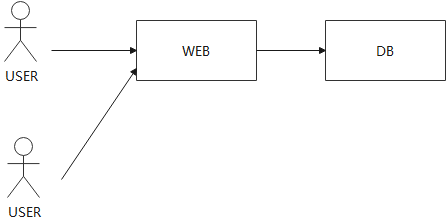
当你只有1-2个用户时,一台计算机就可以运行web服务器和数据,或者一台计算机运行web服务器,一台计算机运行数据库。但是有可能你的网站一夜之间就火了起来,你发现可能有一亿人要登录你的网站。你该怎么修改你的网站,使它能够在一台计算机上支持一亿个用户?你可以花费大量时间极致优化你的网站,但是很显然你没有那个时间。所以,为了提升性能,你要做的第一件事情就是购买更多的web服务器,然后把不同用户分到不同服务器上。这样,一部分用户可以去访问第一台web服务器,另一部分去访问第二台web服务器。因为你正在构建的是类似于Reddit的网站,所有的用户最终都需要看到相同的数据。所以,所有的web服务器都与后端数据库通信。这样,很长一段时间你都可以通过添加web服务器来并行的提高web服务器的代码效率。
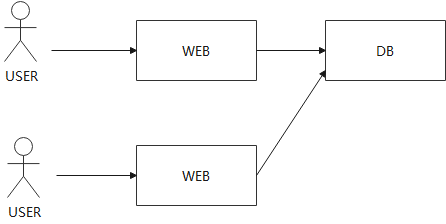
只要单台web服务器没有给数据库带来太多的压力,你可以在出现问题前添加很多web服务器,但是这种可扩展性并不是无限的。很可能在某个时间点你有了10台,20台,甚至100台web服务器,它们都在和同一个数据库通信。现在,**数据库突然成为了瓶颈(bottleneck)**,并且增加更多的web服务器都无济于事了。所以很少有可以通过无限增加计算机来获取完整的可扩展性的场景。因为在某个临界点,你在系统中添加计算机的位置将不再是瓶颈了。在我们的例子中,如果你有了很多的web服务器,那么瓶颈就会转移到了别的地方,这里是从web服务器移到了数据库。
这时,你几乎是必然要做一些重构工作。但是只有一个数据库时,很难重构它。而虽然可以将一个数据库拆分成多个数据库(进而提升性能),但是这需要大量的工作。
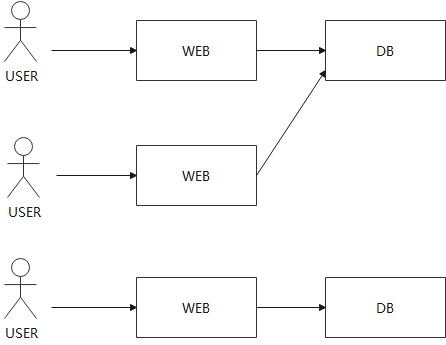
我们在本课程中,会看到很多有关分布式存储系统的例子,因为相关论文或者系统的作者都在运行大型网站,而单个数据库或者存储服务器不能支撑这样规模的网站(所以才需要分布式存储)。
所以,有关扩展性是这样:我们希望可以通过增加机器的方式来实现扩展,但是现实中这很难实现,需要一些架构设计来将这个可扩展性无限推进下去。
1.4 可用性(容错)
由于我们的系统是运行在网络分区的分布式场景下,假设集群中有100台机器,这100台机器通过网络进行连接,那么完全有可能出现机房断电、某人不小心踢掉了网线、网线老化故障,网络交换机故障等各种问题,导致这100台机器中某些机器出现不可用。因为错误总会发生,我们也无法避免错误发生,所以必须要在设计时就考虑,系统能够屏蔽错误,或者说能够在出错时继续运行。即:系统经过精心的设计,即便在发生特定错误的场景下,系统仍然能够正常运行,仍然可以像没有出现错误一样,为你提供完整且正确的服务。
除了可用性,容错还有一个特征称为可恢复性。如果系统出现了无法自动修复的问题时,系统可以停止工作,不再提供服务,之后有人来修复,并且在修复之后系统仍然可以正常运行,就像没有出现过问题一样。这是一个比可用性更弱的需求,因为在出现故障到故障组件被修复期间,系统将会完全停止工作。但是修复之后,系统又可以完全正确的重新运行,所以可恢复性是一个重要的需求。简单理解就是:当系统故障后,故障之前系统的数据不会丢失,再系统修复重启完成后又能继续正确的运行(理解相当于系统暂停了)
为了实现容错的可用性和可恢复性,有两个方案:
采用非易失存储,比如磁盘,磁盘将数据进行永久的物理存储。但使用磁盘会引起性能问题
采用复制,比如多副本机制,如果一个副本挂了,采用另一个副本提供服务。但多副本会引起数据一致性问题。
1.5 一致性
一致性分为强一致性与弱一致性。强一致性通俗来讲就是:你每次Get的值都是上次最近一次Put的值,强一致性可以保证每次Get获取的值都是最新的值。而弱一致性并不会做同样的保证,弱一致性可能提供Get的值可能并不是最新的,也可能是历史的某个旧值,这个旧值甚至可能是很久前写入。你可能会问,有了强一致性,为什么我还需要弱一致性?事实上,在单机环境下强一致性容易实现(利用锁等方式),因为单机不存在网络分区,不需要进行网络通信。而在分布式环境中,各个组件需要做大量的通信,才能实现强一致性。如果你有多个副本,那么不管get还是put都需要询问每一个副本,然后从所有副本中取出最新的值,但是在容错场景下,多个副本在物理上很可能并不在一个数据中心,网络请求可能会跨数据中心,这将会带来系统吞吐性能的直线下降,并且由原来的一个网络IO,变为多副本的多次网络IO,极大的增加了网络带宽压力。
1.6 分布式存储系统设计的难点
首先我们构建分布式系统的出发点一般是为了可扩展性,因为单机的CPU、内存、磁盘、网络、并行计算等性能总是有限的,而分布式系统可以通过购买成百上千台廉价的机器,以实现算力、存储能力等性能同等数量倍数的提升。所以这里引出:1. 性能(可扩展性)是分布式系统的主要目标。而当我们拥有上千台机器后,那么这些机器中随机出现故障的概率就会大大增加,如果机器数量够多,甚至每小时或者每分钟都会有机器出现各种各样的故障,我们不能因为某台机器出现问题导致上千台的集群不可用,所以我们设计的系统需要实现容错,而实现容错的方式一般是采用复制(副本机制),即当节点故障后,采用其复制的副本代替故障阶段继续提供服务即可。所以这里引出:2. 分布式系统需要支持容错能力,容错常见的方式为多副本机制。 有了多副本之后,副本之间的数据同步显得尤为重要,因为稍不小心,在同一个时序下可能会出现副本数据不一致的场景,严格意义上来说它们不再互为副本,而你获取的数据取决于你从哪个副本上获取的,因为不同的副本可能有不同的数据,这里又引起了数据一致性问题。所以这里引出:3. 多副本机制会造成数据一致性问题。 为了避免一致性问题,我们不得不在机器之间做大量的网络交互来处理时序问题以及状态同步,这样势必带来性能的降低,所以这里引出:4. 保证数据一致性需要大量的网络交互,这样势必会降低性能,好的一致性的代价就是低性能。 这与我们构建分布式系统的第一点目标是相违背。
理论上我们可以构建性能很高的系统,但是不可避免的,都会陷入到这里的循环来:为了性能构建然后分布式系统,由于分布式环境下错误是常见的,所以需要支持容错机制,为了实现容错便采用多副本机制,多副本机制又会引起数据一致性问题,为了解决数据一致性又需要大量的网络交互,大量的网络交互势必降低系统性能。 现实中,如果你想要好的一致性,必然性能会受损。如果你不想性能受损,那就要接受数据不一致的行为。但是现实的大多数场景中,人们都不愿意为了一致性牺牲性能。这也是弱一致性存在的主要意义。
对于上述背景,在某些Case中,有些有很好的解决方案,有些甚至到目前为止也没有那么好的解决方案。接下来作者将介绍几种分布式算法,统观各分布式算法,其本质都是在上述的循环内,围绕可扩展性、可用性、一致性上进行不同取舍并做了一些取巧的设计,最后得到了不同的系统设计结果。
2.1 labs实验安排
课程组成部分:
1️⃣ lectures 2️⃣ papers 3️⃣ exams 4️⃣ labs 5️⃣ project(optional)
有四次编程实验。
1️⃣ MapReduce。第一次是一个简单的MapReduce实验。
2️⃣ Raft for fault tolorance。第二个实验实现Raft算法,这是一个理论上通过复制来让系统容错的算法,具体是通过复制和出现故障时自动切换来实现。
3️⃣ K/V server。第三个实验,你需要使用你的Raft算法实现来建立一个可以容错的KV服务。
4️⃣ sharded K/V service。第四个实验,你需要把你写的KV服务器分发到一系列的独立集群中,这样你会切分你的KV服务,并通过运行这些独立的副本集群进行加速。同时,你也要负责将不同的数据块在不同的服务器之间搬迁,并确保数据完整。这里我们通常称之为分片式KV服务。分片是指我们将数据在多个服务器上做了分区,来实现并行的加速。
分数分布如下
2.2 分布式系统的抽象和实现工具
这门课程是有关应用的基础架构的。所以,贯穿整个课程,我会以分离的方式介绍:第三方的应用程序,和这些应用程序所基于的,我们课程中主要介绍的一些基础架构(infrustructure)。基础架构的类型主要是**存储(storage),通信(communication)(网络)和计算(computation)**。
我们会讨论包含所有这三个部分的基础设施,但实际上我们最关注的是存储,因为这是一个定义明确且有用的抽象概念,并且通常比较直观。人们知道如何构建和使用储存系统,知道如何去构建一种多副本,容错的,高性能分布式存储实现。
我们还会讨论一些计算系统,比如今天会介绍的MapReduce。我们也会说一些关于通信的问题,但是主要的出发点是通信是我们建立分布式系统所用的工具。比如计算机可能需要通过网络相互通信,但是可能需要保证一定的可靠性,所以我们会提到一些通信。实际上我们更多是使用已有的通信方式,如果你想了解更多关于通信系统的问题,在6.829这门课程有更多的介绍。
对于存储和计算,我们的目标是为了能够设计一些简单接口,让第三方应用能够使用这些分布式的存储和计算,这样才能简单的在这些基础架构之上,构建第三方应用程序。这里的意思是,我们希望通过这种抽象的接口,将分布式特性隐藏在整个系统内。尽管这几乎是无法实现的梦想,但是我们确实希望建立这样的接口,这样从应用程序的角度来看,整个系统是一个非分布式的系统,就像一个文件系统或者一个大家知道如何编程的普通系统,并且有一个非常简单的模型语句。我们希望构建一个接口,它看起来就像一个非分布式存储和计算系统一样,但是实际上又是一个有极高的性能和容错性的分布式系统。
随着课程的进行,我们会知道,很难能找到一个抽象来描述分布式的存储或者计算,使得它们能够像非分布式系统一样有简单易懂的接口。但是,人们在这方面的做的越来越好,我们会尝试学习人们在构建这样的抽象时的一些收获。
当我们在考虑这些抽象的时候,第一个出现的话题就是实现。人们在构建分布系统时,使用了很多的工具,例如:
1️⃣ RPC(Remote Procedure Call)。RPC的目标就是掩盖我们正在不可靠网络上通信的事实。
2️⃣ threads。另一个我们会经常看到的实现相关的内容就是线程。这是一种编程技术,使得我们可以利用多核心计算机。对于本课程而言,更重要的是,线程提供了一种结构化的并发操作方式,这样,从程序员角度来说可以简化并发操作。
3️⃣ concurrency。因为我们会经常用到线程,我们需要在实现的层面上,花费一定的时间来考虑并发控制,比如锁。
2.3 MapReduce(映射规约)
背景
MapReduce是由Google设计,开发和使用的一个系统,相关的论文在2004年发表。Google当时面临的问题是,他们需要在TB级别的数据上进行大量的计算。比如说,为所有的网页创建索引,分析整个互联网的链接路径并得出最重要或者最权威的网页。如你所知,在当时,整个互联网的数据也有数十TB。构建索引基本上等同于对整个数据做排序,而排序比较费时。如果用一台计算机对整个互联网数据进行排序,要花费多长时间呢?可能要几周,几个月,甚至几年。所以,当时Google非常希望能将对大量数据的大量运算并行跑在几千台计算机上,这样才能快速完成计算。对Google来说,购买大量的计算机是没问题的,这样Google的工程师就不用花大量时间来看报纸来等他们的大型计算任务完成。所以,有段时间,Google买了大量的计算机,并让它的聪明的工程师在这些计算机上编写分布式软件,这样工程师们可以将手头的问题分包到大量计算机上去完成,管理这些运算,并将数据取回。
Google需要一种框架,使得普通工程师也可以很容易的完成并运行大规模的分布式运算。这就是MapReduce出现的背景。
思想
MapReduce的思想是,应用程序设计人员和分布式运算的使用者,只需要写简单的Map函数和Reduce函数,而不需要知道任何有关分布式的事情,MapReduce框架会处理剩下的事情。
抽象来看,MapReduce假设有一些输入,这些输入被分割成大量的不同的文件或者数据块。所以,我们假设现在有输入文件1,输入文件2和输入文件3,这些输入可能是从网上抓取的网页,更可能是包含了大量网页的文件。
input 1
input 2
input 3
MapReduce启动时,会查找Map函数。之后,MapReduce框架会为每个输入文件运行Map函数。这里很明显有一些可以并行运算的地方,比如说可以并行运行多个只关注输入和输出的Map函数。
input 1 -> Map
input 2 -> Map
input 3 -> Map
Map函数以文件作为输入,文件又是整个输入数据的一部分。Map函数的输出是一个key-value对的列表。假设我们在实现一个最简单的MapReduce Job:单词计数器。它会统计每个单词出现的次数。在这个例子中,Map函数会输出key-value对,其中key是单词,而value是1。Map函数会将输入中的每个单词拆分,并输出一个key-value对,key是该单词,value是1。最后需要对所有的key-value进行计数,以获得最终的输出。所以,假设输入文件1包含了单词a和单词b,Map函数的输出将会是key=a,value=1和key=b,value=1。第二个Map函数只从输入文件2看到了b,那么输出将会是key=b,value=1。第三个输入文件有一个a和一个c。
input 1 -> Map (a,1) (b,1)
input 2 -> Map (b,1)
input 3 -> Map (a,1) (c,1)
我们对所有的输入文件都运行了Map函数,并得到了论文中称之为中间输出(intermediate output),也就是每个Map函数输出的key-value对。
运算的第二阶段是运行Reduce函数。MapReduce框架会收集所有Map函数输出的每一个单词的统计。比如说,MapReduce框架会先收集每一个Map函数输出的key为a的key-value对。收集了之后,会将它们提交给Reduce函数。
input 1 -> Map (a,1) (b,1)
input 2 -> Map (b,1)
input 3 -> Map (a,1) (c,1)
Reduce Reduce Reduce
之后会收集所有的b。这里的收集是真正意义上的收集,因为b是由不同计算机上的不同Map函数生成,所以不仅仅是数据从一台计算机移动到另一台(如果Map只在一台计算机的一个实例里,可以直接通过一个RPC将数据从Map移到Reduce)。我们收集所有的b,并将它们提交给另一个Reduce函数。这个Reduce函数的入参是所有的key为b的key-value对。对c也是一样。所以,MapReduce框架会为所有Map函数输出的每一个key,调用一次Reduce函数。
在我们这个简单的单词计数器的例子中,Reduce函数只需要统计传入参数的长度,甚至都不用查看传入参数的具体内容,因为每一个传入参数代表对单词加1,而我们只需要统计个数。最后,每个Reduce都输出与其关联的单词和这个单词的数量。所以第一个Reduce输出a=2,第二个Reduce输出b=2,第三个Reduce输出c=1。
input 1 -> Map (a,1) (b,1)
input 2 -> Map (b,1)
input 3 -> Map (a,1) (c,1)
Reduce Reduce Reduce
result: (a,2) (b,2) (c,1)
这就是一个典型的MapReduce Job。从整体来看,为了保证完整性,有一些术语要介绍一下:
Job。整个MapReduce计算称为Job。
Task。每一次MapReduce调用称为Task。
所以,对于一个完整的MapReduce Job,它由一些Map Task和一些Reduce Task组成。所以这是一个单词计数器的例子,它解释了MapReduce的基本工作方式。
Map函数和Reduce函数
Map函数
Map函数使用一个key和一个value作为参数。我们这里说的函数是由普通编程语言编写,例如C++,Java等,所以这里的函数任何人都可以写出来。入参中,key是输入文件的名字,通常会被忽略,因为我们不太关心文件名是什么,value是输入文件的内容。所以,对于一个单词计数器来说,value包含了要统计的文本,我们会将这个文本拆分成单词。之后对于每一个单词,我们都会调用emit。emit由MapReduce框架提供,并且这里的emit属于Map函数。emit会接收两个参数,其中一个是key,另一个是value。在单词计数器的例子中,emit入参的key是单词,value是字符串“1”。这就是一个Map函数。在一个单词计数器的MapReduce Job中,Map函数实际就可以这么简单。而这个Map函数不需要知道任何分布式相关的信息,不需要知道有多台计算机,不需要知道实际会通过网络来移动数据。这里非常直观。
Map(k,v)
split v into word
for each word w , emit(w,"1")
123
Reduce函数
Reduce函数的入参是某个特定key的所有实例(Map输出中的key-value对中,出现了一次特定的key就可以算作一个实例)。所以Reduce函数也是使用一个key和一个value作为参数,其中value是一个数组,里面每一个元素是Map函数输出的key的一个实例的value。对于单词计数器来说,key就是单词,value就是由字符串“1”组成的数组,所以,我们不需要关心value的内容是什么,我们只需要关心value数组的长度。Reduce函数也有一个属于自己的emit函数。这里的emit函数只会接受一个参数value,这个value会作为Reduce函数入参的key的最终输出。所以,对于单词计数器,我们会给emit传入数组的长度。这就是一个最简单的Reduce函数。并且Reduce也不需要知道任何有关容错或者其他有关分布式相关的信息。
Reduce(k,v)
emit(len(v))




